
Hot Chips Keynote: AMD President Shares Thoughts on AI Pervasiveness
Each year, the keynote presentations at the Hot conference cover the most pressing and important issues in computing. One keynote address this year came from Victor Peng, former president of Xilinx and current president of AMD overseeing several groups, including AI.

AMD's vision for AI pervasiveness relies on energy efficiency and performance at all levels: technology, architecture, system, and DC infrastructure.
In his keynote, "The Journey to AI Pervasiveness," Peng outlined a comprehensive and ambitious roadmap for AI's future and its growing pervasiveness across all computing segments. All About Circuits tuned into the keynote to distill the high-level details of AMD’s AI vision.
AMD and Xilinx's Role in the AI Evolution
According to Peng, companies like AMD and Xilinx drove the evolution of AI to its current ubiquitous state. He traced this journey back to 2012, when deep learning models, notably AlexNet, began leveraging GPUs for accelerated training, leading to a breakthrough in AI performance.

AMD's roadmap has coincided with the evolution of AI.
In 2013, Xilinx introduced another significant milestone: the Zynq-7000 series FPGA SoC. This device integrated a multi-core Arm processor with programmable logic, providing flexibility for AI applications. As AI models grew more complex and required more computational power, AMD responded with the MI100 series in 2020 and, more recently, the MI300X GPU in 2024. The latter was designed specifically for AI inference at scale.
“It's important to co-design,” Peng said. “If you don't optimize hardware together with the algorithms, the models, and the software stack, then you don't see benefits. Indeed, you could actually see degradations.”
AMD considers the MI300X, built on the Infinity architecture, the culmination of a decade-long focus on AI. It features a substantial increase in AI TFLOPS and supports over 1,000 TFLOPS per GPU, making it one of the most powerful AI accelerators on the market.
AI Model Training: The Power Consumption Challenge
As AI models have grown in complexity, their demands on computational resources have also increased, particularly in power consumption.
“In the semiconductive industry, a key figure of merit that you have to worry about is not just performance, but performance and power efficiency,” Peng said.
The keynote highlighted the exponential growth in the energy required to train large AI models, a challenge AMD is actively addressing through innovative architectural designs.
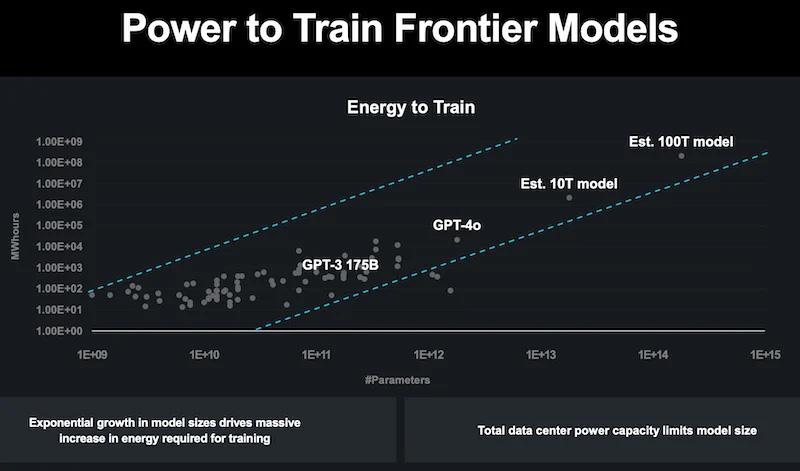
Power to train frontier models
The energy required to train frontier AI models has grown from the hundreds of megawatt-hours for models like GPT-3 to an estimated gigawatt-hour range for future models with trillions of parameters. The MI300X GPU, designed for large-scale AI training, represents AMD's response to this challenge. The GPU directly integrates high-bandwidth memory (HBM) with the compute cores, significantly reducing data movement energy and improving overall energy efficiency.
Peng noted that the total power capacity of data centers is becoming a limiting factor in the size of AI models that can be trained. By focusing on energy-efficient performance, AMD aims to train larger AI models without exacerbating global data centers' significant power consumption.
Differentiating Cloud, Endpoint, and Embedded AI Segments
Finally, Peng discussed how AI's pervasiveness across different computing segments—cloud, endpoint, and embedded—requires tailored approaches to meet each segment's needs.
“The key thing is, there are different orders of magnitude when you go to each of these use cases,” Peng explained. “When you start getting into the embedded world, for example, the requirements or the key objective functions really do get weighted differently.”
In the cloud AI segment, the focus is maximizing throughput and minimizing total cost of ownership (TCO) for large-scale AI deployments. AMD designed the MI300X GPU with these priorities, offering high computational density and efficient interconnects that support the massive parallelism needed for AI training and inference in data centers. The GPU's architecture enables direct connectivity of up to eight OAMs via AMD's Infinity Fabric, providing nearly 900 GB/s of bandwidth, a critical feature for handling the massive data loads characteristic of cloud AI workloads.
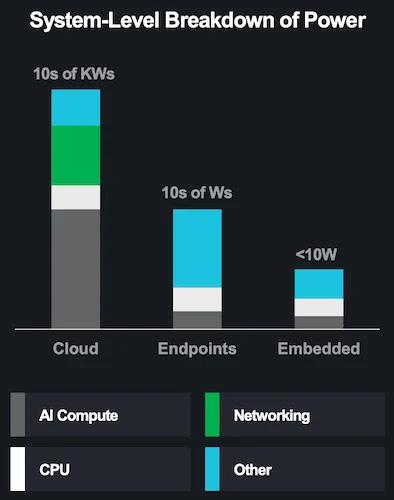
System-level breakdown of power based on segment
Endpoint AI, which includes devices like PCs and notebooks, presents a different set of challenges. Here, the emphasis is on achieving interactive latency and optimizing user experience while balancing power consumption. AMD's Strix Point architecture integrates up to 12 Zen cores, RDNA 3.5 GPU cores, and a 50 TOPS NPU. The heterogeneous architecture efficiently distributes workloads across specialized cores, ensuring that AI tasks are handled by the most appropriate processing unit, whether it's the CPU, GPU, or NPU.
Embedded AI represents the most constrained segment in terms of power and form factor. Applications in this segment, such as automotive or industrial robotics, require real-time processing capabilities with strict latency requirements. AMD's Versal AI Edge products are tailored for these use cases, offering a combination of FPGA programmability and dedicated AI engines. The architecture supports tens of AI TOPS per SoC, focusing on customization and low-latency performance. This makes it suitable for safety-critical applications where timely processing is paramount.
AMD Prods AI Toward a Sustainable Future
As AI permeates every facet of computing, from cloud data centers to embedded systems, developers must innovate processing architectures to meet the mounting challenges to power consumption and performance. With products like the MI300X GPU and others, AMD hopes to build a portfolio that ensures that AI's journey toward pervasiveness is sustainable and impactful.
“When I started out in '82, I liked to think of it as a golden age of computing and semiconductors,” Peng concluded. “But I never thought that at the end of my career, after these orders in magnitude [of performance increases], it would also feel like the new golden age of computing and semiconductors as well.”



